The biggest news for this week is that I’ve had my last final of this semster finished.
Well… Not many works I’ve done due to dealing with those finals. However, as the good news suggests, I’ll have more time from now on to work on. Things will be better. The tough issue ID-103 is still ahead of me.
Done
After lots of discussion… I’ve fixed this LDAP issue reported by Michael. Something related with LDAP was wrong, but I don’t know where it is. However, I’m pretty sure, it shouldn’t be Dashboard’s fault form the log file.
I’ve mainly done two things this week, finishing ID-89 and ID-102.
There is not much to talk about ID-102, just deleting and replacing… For ID-89, refactoring ldap.js, It’s been a long time that I noticed that operations related with ldap.js would be much slower than the ordinary. After checking the search operations, I found that the old one will use search which has baseDN of ou=users,dc=openmrs,dc=org and a filter of uid=USERNAME. Then inspired by intuition, I realized that LDAP server may highly possible first fetch all entries under baseDN and then use that filter to select the items. This would be intolerant in production, as we can directly find the entry via DN of uid=USERNAME,ou=users,dc=openmrs,dc=org.
After performing a little experimentation on my machine and proving that search with direct DN would be 1 times more faster than with filter. I rewrote all the operations in the new ldap.js. Hence, this time, the refactor doesn’t only focus on logic flow and readabilities, but also efficiency.
Well… Exam period is coming… For the sake of GPA, I have to spend lots of time on reviewing. Hence, commits were getting less.
However, goodnews is that the midterm goals are kind of easier compared to those final, and I’ve finished a lot. Currently I’m working on managing front-end dependencies by Bower, which is a npm-like package management tools. Though the task itself is rather easy, all I need to do is find the referrence and replace it, some parts of codebase of Dashboard are kind of aged with lots of deprecated code and dependencies that sometimes will confuse developer, namely me for now. So besides adorpting Bower, I’m also reviewing our code-base to filter out-dated parts which would make things easier in the future. That’s work related with ID-102
Also, I’ve been working on ID-89 as well which aims to refactor ldap.js and add tests.
The first week has passed with not too many troubles, and I hope that this could last for the whole summer. :)
Though having pressure to deal with school works as well, I still managed to deliver some simple work. It’s ID-105 that concerns about creating and synchronizing the OpenMRS-ID with Talk’s account system.
Well, originally I thought this would be a simple task that only costs a few hours. However, it’s not that easy. From my work log, I can recall that I’ve spent one and a half day to get the testing environment set up. The Discourse has a paucity of documentation, like many start-up opensource projects, and it’s also a Ruby on Rails project, which is a technique I’m totally unfamiliar with. And after setting up the environment, I then used a day to mess around with its API, which turns out to be inappropriate. :/ So exhausted I am, I decided to use the brutal-force way, which is to imitate user’s login behaviour as SSO will handle the sync automatically.
Right before I deliver my PR, Robby notified me about the newly added PR convention of OpenMRS listed here. The guide suggests us to use git rebase to squash all commits into one and then make the PR. That’s indeed very thoughtful idea. It’s a pity that I only know this now. And then I wrote another script for syncing current accounts.
Anyway to sum up briefly:
What I Have Done
Added an auto-sync hook for TALK.
Wrote a script to import current accouts.
Actually…… It’s not so much that I have done. Sorry, used a few days to get familiar to development again.
Well, I’ve been luckily enough to get selected in this year’s GSoC with OpenMRS again.
I’ll continue to work on the Dashboard, to make it a better and mature platform, as the works I did last year was a rookie’s first trial. Though it has been running well for quiet a long time, there are appreicably problems remained, as mentioned here
I hope I’ll solve those problems during this summer, and present a better ID Dashboard.
我主要参考了Linux Devices Drivers, Third Edition(LDD3)这本书,有关字符设备的内容在第三章以及第六章,另外该书的源码在github上有,here。愿意深入研究的同学可以去看一下。(注意:LDD3针对的是2.6,如果使用的是3.x版本需要修改一些地方,我的Ubuntu是3.13)
/* There may be multiple readers, so the use of loop is necessary */ while (dev->buffer == dev->wp) { /* nothing to read, wait for inputs */ up(&dev->sem);
if (wait_event_interruptible(dev->inq, (dev->buffer != dev->wp))) return -ERESTARTSYS; /* Loop and reacquire the lock */ if (down_interruptible(&dev->sem)) return -ERESTARTSYS; }
while (dev->buffer != dev->wp) { /* the old data haven't been retrieved */ up(&dev->sem); if (wait_event_interruptible(dev->outq, (dev->buffer == dev->wp))) return -ERESTARTSYS; /* P and loop again */ if (down_interruptible(&dev->sem)) return -ERESTARTSYS; }
Major = register_chrdev(0, PLYPY_DEV_NAME, &fops); if (Major < 0) { return Major; } printk(KERN_INFO "The %s is assigned major number %d", PLYPY_DEV_NAME, Major); printk(KERN_INFO "Use 'mknod /dev/%s c %d 0' to create a file", PLYPY_DEV_NAME, Major); return0; }
staticvoidplypy_exit(void) { unregister_chrdev(Major, PLYPY_DEV_NAME); printk(KERN_INFO "The %s is destroyed", PLYPY_DEV_NAME); }
staticintplypy_proc_show(struct seq_file *m, void *v) { struct task_struct *task; int i = 0; seq_printf(m, "Kernel version: %s\n", utsname()->release); seq_printf(m, "Processes, to name a few:\n"); for_each_process(task) { if (i++ > 9) break; // show only 10 processes at most seq_printf(m, "%s [%d]\n", task->comm, task->pid); } return0; }
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/sched.h>
#include <linux/utsname.h>
#include <linux/kernel.h>
asmlinkage long sys_plypy_hello(void)
{
struct task_struct *task;
int i = 0;
printk("Kernel version: %s\n", utsname()->release);
printk("Processes, to name a few:\n");
for_each_process(task)
{
if (i++ > 9) break; // show only 10 processes at most
printk("%s [%d]\n", task->comm, task->pid);
}
return 0;
}
Though I’ve been coding algorithm contests since high school, when I was an OIer, and for 5 years till now. I’ve never really achieved something big in the algo contest field, due to having been lack of persistence and being distracted by other annoying things from time to time, and most of all, the limit of gift(:/). End of the sad story.
However, I’ve decided to make some changes by starting to get my color red in Codeforces. Actually you can see the story above pretty much by my rating curves…
Anyway, I’ve practiced the Rockethon 2015, here are some conclusions.
A. Game:
Silly problems.
B. Permutations:
The constraint will largely reduce the number of valid permutations. Let’s view this sum by the contribution each individual number made. In the largest cases, the 1 is counted n times, n-1 times for 2, n-2 times for 3… Thus, to make this happen, 1 should be placed at either end of the spots, 2 should be placed at one end of the remaining spots, and so on. Hence, there are 2^n valid sequences, and the first 2^n-1 start with 1, and others end with 1, then in these subsequences, the first half start with 2 and the second half end with 2 and so on. And so goes the way that we generate the kth lexicographical sequence.
C.
Since n is at most 5, and R is at most 10000, brute-force can be safely used. So we classify the bidders into 3, the ones that bid lower than the second price, those who bid equally, and those who bid higher. Notice that there are 2 cases, the first is that 1 highest bid and several second bids and the second is that the highest bid has the value as the second one.
A week ago, the 5th semester of my university life had ended. It was not bad,
I had new things learned, new concepts adopted, few old minds enhanced, few
essential questions discovered, and maybe myself found.
Anyway, I’m sitting in my home, wondering the future, which is full of uncertainties.
Enough for the garbages, I’m not good at playing with words, especially not in
my first language. Let’s note something real, those bricks that I, a
hard-working brick-carrier, want to carry this winter.
The emacs adventure
While I was working on the OpenMRS-ID project, my once trusty editor Sublime
Text 2 went broken. It just goes freeze from time to time and made me
angry. Few months ago, I had a thought about trying to learn emacs. However,
being scared about the complexity of ‘the Emacs Operating System’, and
satisfied what I had in ST2, I forgot this gradually.
But as my ST2 went down, ‘We shall all be crazy once in a while, and it’s the
perfect time to be crazy’, I thought. So I decided to give emacs a try, and
downloaded it, and began to read the tutorial. ‘Oh WTF…’ There were just so
many C-key and M-key keystrokes to memorize. As a VIM-like keybinding user, I
cannot feel even slightly confortable with it, however, those emacs packages,
like ORG-mode, are so attractive. So I googled ‘emacs + vim keybinding’.
Because you are either a vi person or an emacs person. The same way you’re either a dog person or a cat person.
And, anyway, emacs with its strange command sequence like
CTRL META LEFTSHIFT RIGHTSHIFT WINDOWS OPENAPPLE ALT K
is better suited to aliens with 87 fingers, or elite pianists :-)
However, I found the Evil package, like those other vim add-ons on other
IDEs/editors. It was amazing, just amazing.
Ah, finally the Emacs OS get a good editor, evil.
The adventure so far was fun, I’m still learning the Emacs Operating System.
The Rasberry Pi OS
As we’ve learnt OS this semester, so I want to try my skills. And by suggestions
of one my older fellow student(Xue Zhang). I dived into the
Baking Pi
online course provided by Cambridge University. Well, I was f##ked… it has
nothing to do with modern OS development, but merely some low-level programming
with ARMv6 assembly.
Anyway, it’s still somehow interesting, and I’ve put my works
here.
Other bricks
The network and SDN stuff
Concrete Mathematics ( Bible of brick-carrying )
Coursera courses
Yale’s Introduction to Classical Music
NTU’s Machine Learning Techniques ( A lot to catch up… )
Literature
Love in the Time of Cholera ( El amor en los tiempos del colera )
A Tale of Two Cities ( And other Charles Dickens books I bought )
Some real OS stuff ( minix maybe? )
This will be an fulfilling summer, at least the plan is…
The father 6281 created, pid1:6282pid2:6283
The father 6282 created, pid1:0pid2:6284
The father 6284 created, pid1:0pid2:0
The father 6283 created, pid1:6282pid2:0
Strange, huh? There is 4 processes created, rather than 3 that we expected; and the child process 6282 has also created one process 6284.
Well, let’s explain this. The fork will create a duplicate of the running process, and the process created will be the child of the original process. Since the child is a replica, it will have the same local variables ,same PC(program counter) and a bunch of other stuff you may see its man page for details.
See the child and the parent processes are almost identical, the child will have the same PC as the parent’s, which means, it will continue to execute the code after where fork is called. And that is the reason of the “wrong” behavior we have above. The execution flow goes like this.
Parent 6281 created child 6282, then 6281 & 6282 will continue to execute pid2 = fork()
6281 created another child 6283, while child 6282 also created one child of its own, 6284.
Then how shall we distinguish the child and the parent? Notice that some pids are 0. After fork returned the child and the parent will receive 2 different value. The parent will get the pid of its child, meanwhile the child will have a 0. Also -1 for failed duplicate. And we can work on that.
Signal and Kill
In this task, we used software interrupt to achieve interprocess communication.
That is, one process listen for a specific signal (interrupt) and then the other one send that signal. These are done by signal and kill respectively.
The signal(signum, handler) will bind the specified signal with id signum with the handler function handler. And kill(pid, sig) will send signal sig to process pid.
Design
Then everything is simple, as the task asked us to let the parent listen for keyboard interrupt and then send signal to kill the children. We shall simply let the parent listen to the SIGINT, and then bind a handler function that will send signals to the 2 children, the children then wait for the signals to commit suicide.
However, there are few things to note.
Notes
The guide provided is… well, it made few mistakes. Only on some specific OS the break and delete will generate the SIGINT, mostly it’s for Ctrl+c. And since we are using SIGINT, it’s vital to overwrite the orignal handler for it. Or it will cause the processes to terminate, though the outcome is same, it’s not what we want.
int main(int argc, int *argv[]) { // make all process of this group ignore the normal soft interrupt signal(SIGINT, SIG_IGN); // create child process 1 while (-1 == (pid1 = fork())) continue;
if (pid1 > 0) { // parent // create child process 2 while (-1 == (pid2 = fork())) continue;
void suicide(int signum) { printf("Process %ld is committing suicide, by signal %d\n", (long) getpid(), signum); exit(EXIT_SUCCESS); }
Pipe
The task 2 demand us to implement another interprocess communication via pipe.
Well it’s rather easy, as we already got here. Use pipe to create a communication tunnel, and use that to pass messages. But notice there are 2 process writing to that pipe concurently, so proper lock is needed. Check lockf.
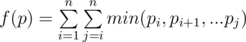 will largely reduce the number of valid permutations. Let’s view this sum by the contribution each individual number made. In the largest cases, the 1 is counted n times, n-1 times for 2, n-2 times for 3… Thus, to make this happen, 1 should be placed at either end of the spots, 2 should be placed at one end of the remaining spots, and so on. Hence, there are 2^n valid sequences, and the first 2^n-1 start with 1, and others end with 1, then in these subsequences, the first half start with 2 and the second half end with 2 and so on. And so goes the way that we generate the kth lexicographical sequence.
will largely reduce the number of valid permutations. Let’s view this sum by the contribution each individual number made. In the largest cases, the 1 is counted n times, n-1 times for 2, n-2 times for 3… Thus, to make this happen, 1 should be placed at either end of the spots, 2 should be placed at one end of the remaining spots, and so on. Hence, there are 2^n valid sequences, and the first 2^n-1 start with 1, and others end with 1, then in these subsequences, the first half start with 2 and the second half end with 2 and so on. And so goes the way that we generate the kth lexicographical sequence.